机器学习研究内容
机器学习研究的主要内容是从数据中产生“模型”的算法,即学习算法。
“模型”泛指从数据中学得的结果。
从数据中学得模型的过程称为“学习”或“训练”,这个过程通过执行某个学习算法来完成。训练过程中使用的数据称为“训练数据”,其中每个样本称为“训练样本”,训练样本组成“训练集”。
机器学习的前提:
- 数据中存在模式
- 模式无法形式化描述
- 有充分的数据
以此来讲,机器学习是基于一定的假设,从数据中学习出模式的过程。
机器学习的目标是使学得的模型能很好的适用于“新样本”,而不是仅仅在训练样本上工作的很好;即便对聚类这样的无监督学习任务,我们也希望学得的簇划分能适用于没在训练集中出现的样本。学得模型适用于新样本的能力,称为“泛化”(generalization)能力。
学习的可行性
样本和整体的关系
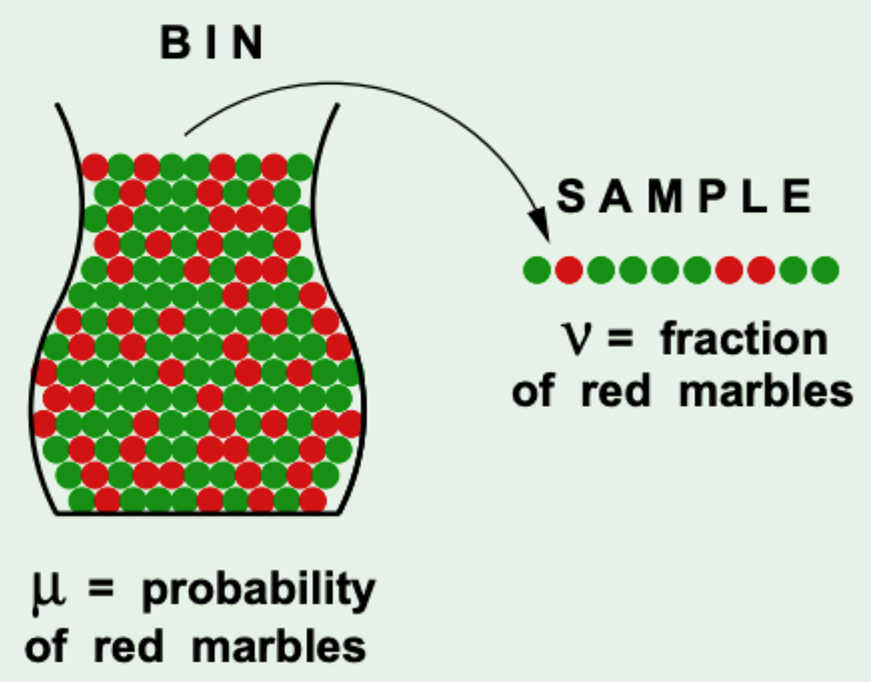
- 在大样本的场景下,样本频率v可以任意精度逼近总体概率u
- Hoeffding不等式
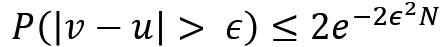
- Bound与u无关
- 无分布假设
- 数据量足够大,就可以用样本估计值代表真实值
机器学习问题分类
监督学习(supervised learning):训练数据有标记(label)信息。
在监督学习下,输入数据称为“训练数据”,每组训练数据都有明确的标识或结果,如反垃圾邮件系统中的“垃圾邮件”和“非垃圾邮件”,手写数字识别中的“1”、“2”、“3”、“4”。在建立预测模型时,监督学习建立学习过程,将预测结果与“训练数据”的实际结果进行比较,并不断调整预测模型,直到模型的预测结果达到预期的准确率。
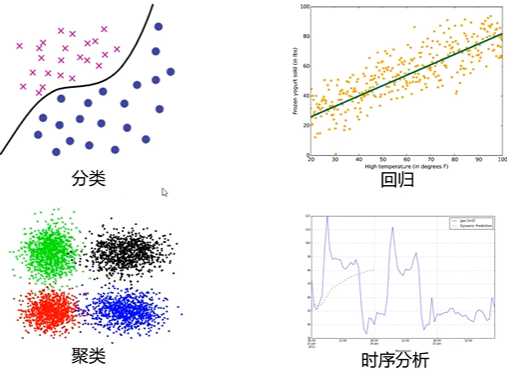
- 预测的是离散值,此类学习任务称为“分类”(classification)
- 涉及两个类别分类时:“二分类”(binary classification)任务
- 涉及多个类别分类时:“多分类”(multi-class classification)任务
- 预测的是连续值,此类学习任务称为“回归”(regression)
- 常见的算法包括逻辑回归和反向传播神经网络。
无监督学习(unsupervised learning):训练数据无标记信息。
在无监督学习中,数据不是特别确定的,学习模型是为了推断数据的一些内部结构。常见的应用场景包括学习关联规则和聚类。常见的算法包括Apriori算法和k均值算法。
“聚类”(clustering)将训练集中的数据分成若干组,每组称为一个“簇”(cluster)
半监督学习
在这种学习模式下,输入数据部分被识别,部分不被识别。这种学习模型可以用于预测,但是该模型首先需要学习数据的内部结构,以便合理地组织用于预测的数据。应用场景包括分类和回归。该算法包括一些常用监督学习算法的扩展。这些算法首先尝试对未标记数据建模,然后预测标记数据。图形推理或拉普拉斯SVM等。
强化学习
在这种学习模式中,输入数据被用作模型的反馈,与监督模型不同,输入数据仅被用作检查模型是对还是错的一种方式。在强化学习下,输入数据直接反馈给模型,模型必须立即进行调整。常见的应用场景包括动态系统和机器人控制。常见的算法包括问学习和时间差学习
在企业数据应用的背景下,监督学习和非监督学习的模型可能是最常用的。在图像识别等领域,由于存在大量未标记数据和少量可识别数据,半监督学习是目前研究的热点。然而,强化学习更多地应用于机器人控制和其他需要系统控制的领域。
模型参数
- 模型自身参数:通过样本学习得到的参数,如神经网络中的权重及偏置量等;
- 超参数:模型框架的参数,如kmeans中的k,神经网络中的网络层数及每层的节点个数,通常由手工设定。
机器学习步骤
定义函数(选择算法)→定义函数优劣(评价指标)→选择最优函数
经验误差与过拟合
一般地,把学习器实际预的测输出与样本的真实输出之间的差异称为“误差”,在训练集上的误差称为“训练误差”或“经验误差”,在测试集合上的误差称为“泛化误差”。
我们希望得到泛化误差小的学习器,但是由于事先不知道新样本的状态,只能努力使经验误差最小化。
我们实际希望的是,是在新样本上表现得很好的学习器。为达到这个目的,应该从训练样本中尽可能学出适用于所有潜在样本的“普遍规律”,这样才能在遇到新样本时做出正确的判别。然而,当学习器把训练样本学得“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降。这样的现象在及其学习中称为“过拟合”。与“过拟合”相对的是“欠拟合”,这是指对训练样本的一般性质尚未学好。
过拟合是无法彻底避免的。
过拟合的含义:
- 过度关注训练集(VC维过大)
- 对抗变化能力差(泛化能力差)
1 | import numpy as np |
假设空间
归纳和演绎是科学推理的两大基本手段。
归纳是从特殊到一般的“泛化”过程,即从具体的事实归结出一般性规律。比如,“从样例中学习”的模型训练过程。
演绎是从一般到特殊的“特化”过程,即从基础原理推演出具体状况。比如,基于一组公理和推理规则推导出与之相恰的定理。
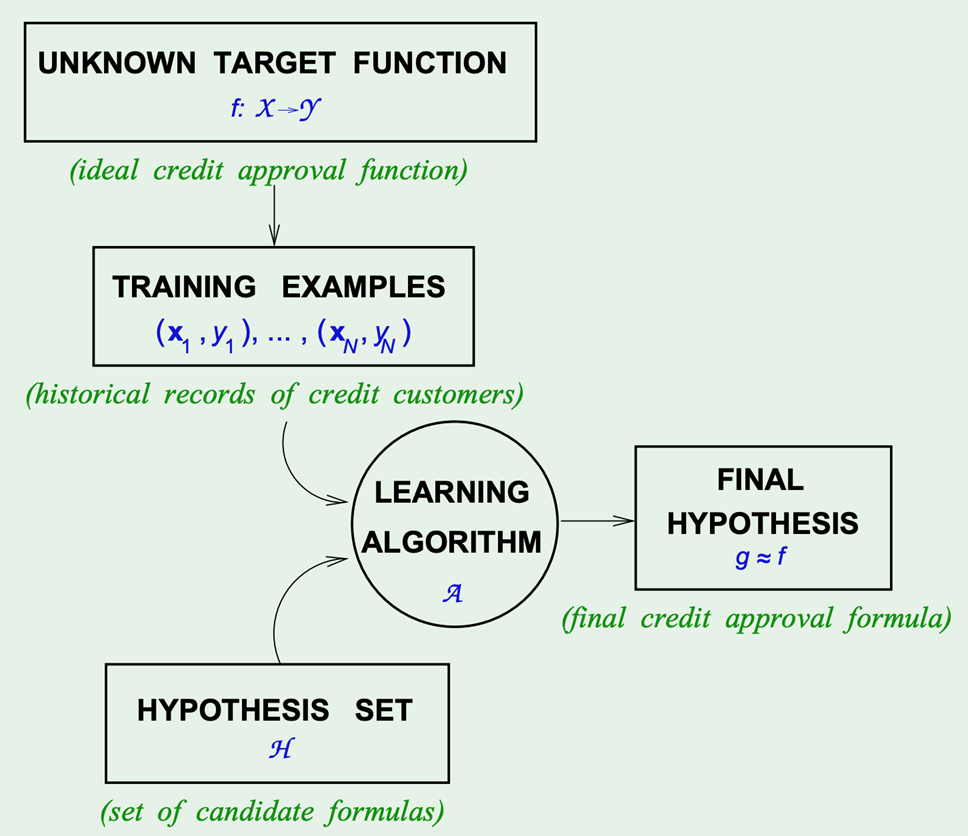
把学习过程看作一个在所有假设组成的空间中进行搜索的过程,搜索目标是找到与训练集相匹配的假设,即能够将训练集的标记判断正确的假设。
假设的表示(模型的形式)一旦确定,假设空间及其规模大小就确定了,可以利用各种策略对这个假设空间进行搜索,搜索过程中可以不断删除与样本集“样本-标记”不一致的假设,最终会获得与训练集一致(即对所有训练样本能够进行正确判断)的假设,此时剩下的假设空间就是学得的结果。
现实问题中我们常面临很大的假设空间,但学习过程是基于有限样本训练集进行的,因此,可能有多个假设与训练集一致,即存在着一个与训练集一致的“假设集合”,称之为“版本空间”(version space)。
归纳偏好(如何衡量一个假设空间?)
归纳偏好可以看做学习算法自身在一个可能很庞大的假设空间中对假设进行选择的启发式或“价值观”。
归纳偏好对应了学习算法本身所做出的的关于“什么样的模型更好”的假设。在具体问题中,这个假设是否成立,即算法的归纳偏好是否与问题本身匹配,大多数时候直接决定了算法能否取得好的性能。
“没有免费的午餐”(No Free Lunch Theorem, NFL)定理表明无论学习算法多好或者坏,它们的期望性能是相同的。
NFL定理最重要的意义,是让我们清楚地认识到,脱离具体问题,空泛地谈什么算法更好是没有意义的,每种算法都有自己的适用范围,针对自己的实际问题,根据算法自身的归纳偏好,找到匹配当前问题的局部最优解,该解可能在其他问题上表现不尽如人意,但是这就足够了。
假设空间的衡量:
衡量一类模型的分类能力:VC Dimension
VC维:假设空间能shatter(对数据任意组合分类)的最大数据量
平面中线性模型的VC维等于3,也就是平面中任意3个点(无论如何取值)总能被一条直线分开。
VC维要足够大
用来拟合足够复杂的数据
- VC维和参数量大致相等
- 复杂模型、更多参数需要更大的VC维
VC维要被制衡(不能太大)
- 用来保证训练集以外的效果
- 正则化制衡VC维
衡量一类模型对抗变化的能力(泛化能力)
正则化
正则化核心思想是通过限制假设空间,制衡VC维,以控制模型复杂度。因为模型复杂度越高,越容易过拟合。
线性模型
- L1、L2
- 限制参数大小、数量
树模型
- 限制深度
- 限制数量
- 限制分列条件
平衡(通过λ实现平衡)损失函数和模型复杂度(模型学习到的权重越大,模型复杂度越高,以权重表示模型的复杂度)。
minimize: Loss(Data|Model) + complexity(Model)
例如,L2正则化损失函数
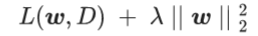
λ值越大,正则化越强,表示需要更多关注模型的复杂度,适用于测试集中的样本与训练集中的样本相差比较大时;
λ值越小,正则化越弱,表示需要更多关注损失函数,适用于测试集中的样本与 训练集中的样本相差不是很大。
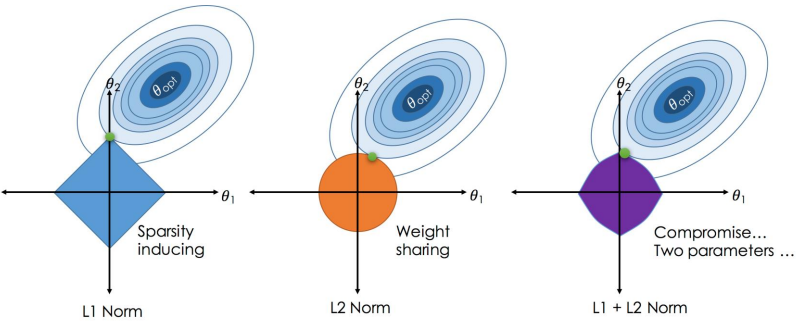
L1正则化是通过计算权重的曼哈顿距离,L2正则化是通过计算权重的欧氏距离表示模型的复杂度。如上图所示,正则化要平衡损失和模型复杂度,人为的让权重不仅获得较小的损失,还要满足正则规则,即由上图中θ转移到绿色的点。

