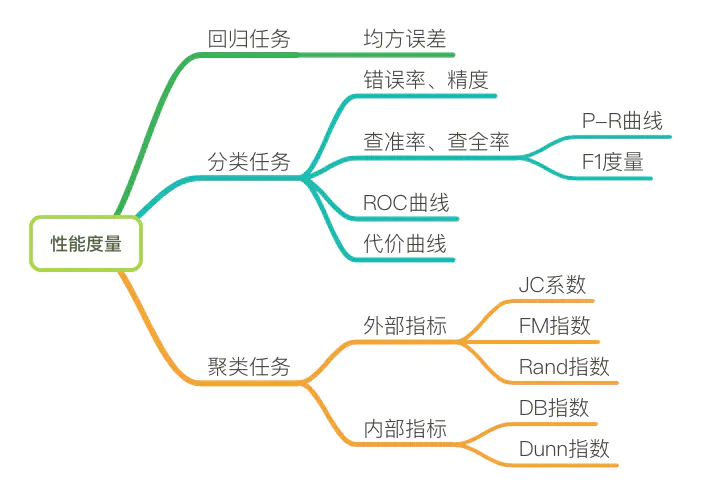
衡量模型泛化能力的评价标准是性能度量(评价指标)。
准确率(accuracy)是最常见的一种评价指标。但是准确率越高,模型就越好么?假设,在1000个样本中,有999个正样本,1个负样本(不均衡数据集) 如果全部预测正样本,就可以得到准确率99.9%!这样的场景有:信用卡欺诈检测,离职员工检测等。有些任务更关心的是某个类的准确率,而非整体的准确率。
回归模型中常用的评价指标(损失函数)
- sklearn.metrics.r2_score() R2决定系数
- sklearn.metrics.mean_absolute_error() MAE平均绝对误差
- sklearn.metrics.mean_squared_error() MSE均方误差
- np.sqrt(metrics.mean_squared_error()) RMSE均方根误差
- sklearn.metrics.mean_absolute_percentage_error() MAPE平均绝对百分比误差
- sklearn.metrics.median_absolute_error() 中值绝对误差
更多评价指标:http://scikit-learn.org/stable/modules/model_evaluation.html
分类模型评价指标
错误率和精度
分类错误的样本数占样本总数的比例称为“错误率”
精度=1-错误率。
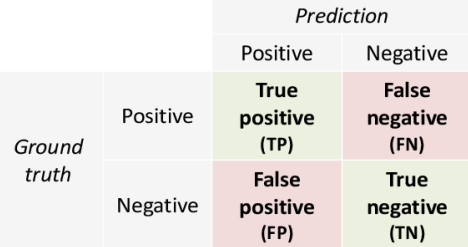
- 真正例(TP),预测值是1,真实值是1。被正确分类的正例样本。
- 假正例(FP),预测值是1,但真实值是0。
- 真反例(TN),预测值是0,真实值是0。
- 假反例(FN),预测值是0,但真实值是1。
- TPR(Recall,查全率/召回率):TP/(TP + FN)。在所有实际值为1的样本中,被预测为1的比例。
- Precision(查准率):TP/(TP + FP)。在所有预测值为1的样本中,实际值为1的比例。
- FPR:FP/(TN+FP),在所有实际值是0的样本中,被预测为1的比例。
F1值
将查全率和查准率用一个数值表示:
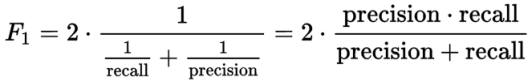
sklearn.metrics中包含常用的评价指标
- accuracy_score
- precision_score
- recall_score
- f1_score
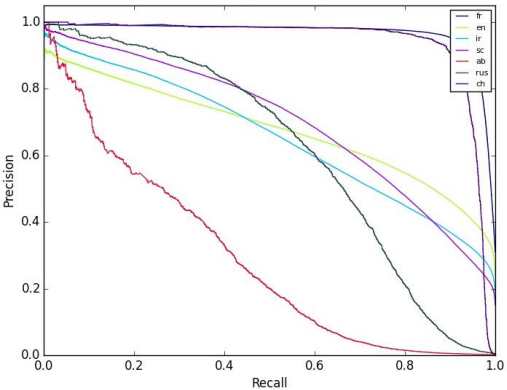
Precision-Recall Curve(PR曲线)
- x轴:recall,y轴:precision(可交换)
- 右上角是“最理想”的点,precision=1.0,recall=1.0
- sklearn.metrics.precision_recall_curve()
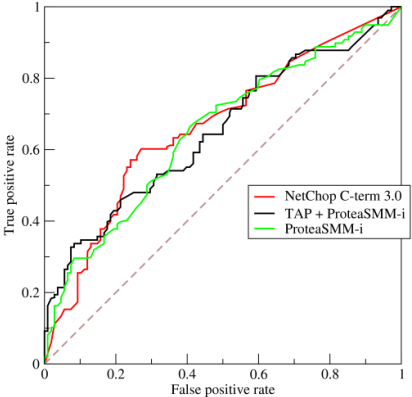
Receiver Operating Characteristic Curve(ROC曲线)
- x轴:FPR,y轴:TPR
- 左上角是“最理想”的点,FPR=0.0,TPR=1.0
- sklearn.metrics.roc_curve()
AUC的值就是ROC曲线下的面积:
- AUC在0~1之间。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
混淆矩阵(confusion matrix)
- 可用于多分类模型的评价
- sklearn.metrics.confusion_matrix()